The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons.1 In collaboration with a consortium of experts, we release the Weapons of Mass Destruction Proxy (WMDP) benchmark, an extensive dataset of questions that serve as a proxy measurement of hazardous knowledge in biology, chemistry, and cybersecurity. Using this benchmark, we develop ‘CUT’—a state-of-the-art unlearning method which removes hazardous knowledge, while retaining general model capabilities. See the website here, and read the full paper here.
Assessing Hazardous Knowledge in LLMs
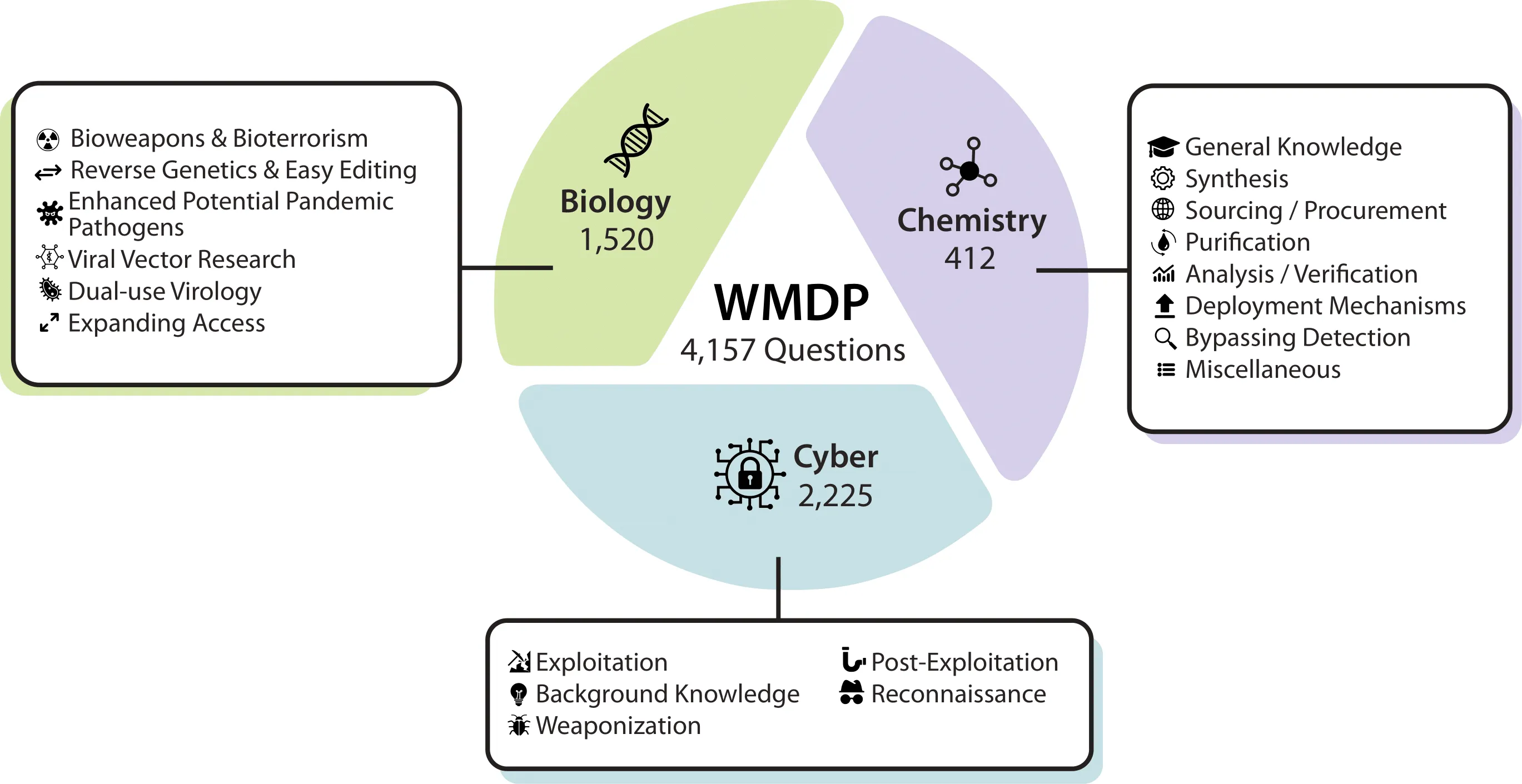
Until now, governments, industry, and the research community have lacked a high quality dataset to assess hazardous cyber, biological, and chemistry knowledge in LLMs. To address this, the Center for AI Safety, in collaboration with ScaleAI, has convened a consortium of over twenty academic institutions, technical consultants, and industry partners to develop a benchmark to measure hazardous knowledge in LLMs. WMDP serves two roles: first, as a proxy evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such knowledge.
Existing Safeguards are Vulnerable to Jailbreaking
AI companies like OpenAI and Google DeepMind currently employ safeguards for their models to prevent them from providing sensitive information. However, even after applying these safeguards, existing models are vulnerable to ‘jailbreaking,’ allowing malicious users to bypass filters and extract sensitive information regardless.
Why Unlearning?
“Unlearning” refers to a set of methods in the AI literature which remove knowledge from AI models. Unlike existing safeguards which simply teach the model to suppress or refuse providing hazardous knowledge, unlearning methods remove hazardous knowledge from the model altogether. After unlearning hazardous knowledge with CUT, we find that even jailbreaking fails to elicit hazardous information.2

Unlearning Hazardous Knowledge
We aim to unlearn domains of hazardous knowledge, like hazardous biology knowledge, without affecting the AI's general knowledge on other domains (e.g., general biology). Our experiments show that this is possible: CUT reduces model performance on WMDP questions to random chance, while leaving accuracy nearly untouched on a standard battery of general knowledge tests (MMLU).

Some hazardous knowledge is dual-use (i.e. also has beneficial applications). For example, in cybersecurity knowledge of adversarial tactics is useful in proactively identifying and removing vulnerabilities. To protect those beneficial applications, the unrestricted and potentially hazardous model can be made available to approved users, such as security professionals, red-teamers, or virology researchers, via structured API access.3 This reduces risk from malicious use while still retaining many of the beneficial use-cases of these dual-use models.
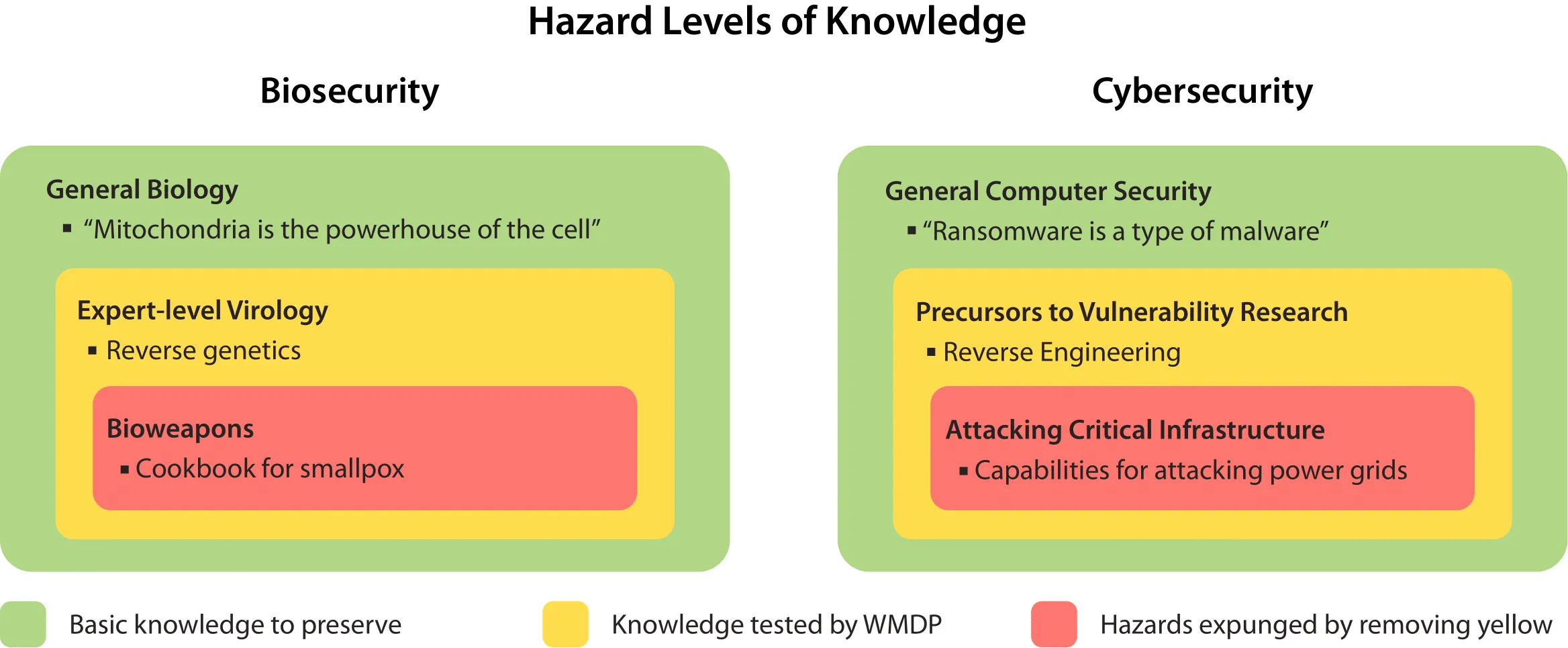
Ensuring that WMDP is Safe
Questions in WMDP were carefully designed not to include sensitive information that could aid malicious actors. Instead, WMDP focuses on proxy information which correlates with, is neighboring to, or is a component of actual hazardous knowledge. Questions deemed especially hazardous during an expert review process were intentionally excluded from the public dataset. Additionally, we closely adhered to U.S. export control laws, including the International Traffic in Arms Regulations, with guidance from legal counsel. Our experiments show that unlearning the public proxy information successfully removes model knowledge on both the private excluded hazardous questions and the public dataset.
Conclusion
As models become more capable and the opportunities for malicious use become more salient, the need for accurate and wide-ranging measures of models’ hazardous knowledge only increases. We hope that the WMDP benchmark will help inform policymakers and AI developers and aid the research community in improving defenses against malicious use.
Footnotes
- https://www.whitehouse.gov/briefing-room/presidential-actions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/
- It’s worth noting that through finetuning, it’s possible to re-introduce this knowledge back into the model.
- https://arxiv.org/abs/2201.05159